Launch AI Agents so you can spend more time doing what you love in your life and business

Free human & agent tools
- 8 AI department-head agents
- Copy-paste prompt & skill packs
- Your personal AI map, built for you
Create your free AI agent commander account
Already registered?
No spam. Unsubscribe anytime.
Start with the goal
Build on the 90/10
The goal is simple: let AI handle 90% of the work, the busywork, the admin, the things that drain you, so you can spend 100% of your time on the 10% you actually love. That's where you do your best work and feel most alive. Everything here is built to get you there.
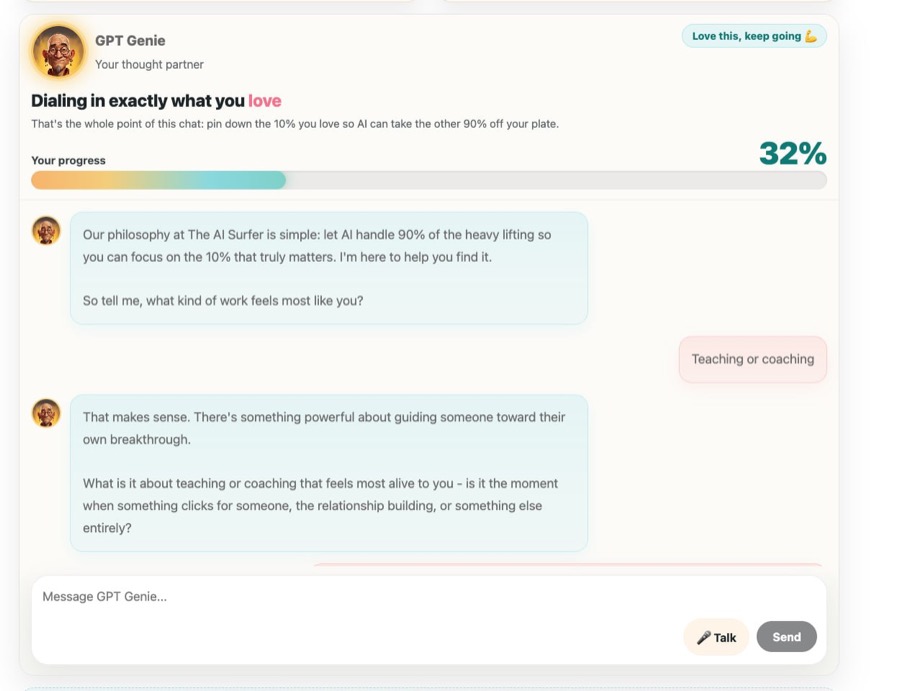
Step 1 · Meet GPT Genie
A short chat that finds your 10%
No forms, no homework. GPT Genie is your thought partner. You just talk, and it asks the right questions to get you crystal clear on the work you actually love, and the work you'd rather hand off to AI.
- A real conversation, not a quiz, that takes a few minutes
- Pinpoints your North Star, your 10%, and your 90%
- Builds your personal map + ready-to-use files for your agent automatically
Step 2 · What you unlock, free
Then build your AI team with the Agent Command Kit
Once you know your 90%, the Agent Command Kit is the shortcut to handing it off. Here is what is waiting inside.
AI Department Heads
Spin up a CFO, CMO, VP of Sales, COO and more. Copy a prompt, paste it into Telegram, and your agent runs that department in the background.
Copy-Paste Prompt Packs
Battle-tested prompt packs for memory, lead gen, knowledge extraction, and self-checking goals. Tap, copy, paste, done.
Super Agent Skill Packs
Curated skills for vibe coding, security, and more. Drop a SKILL.md into your agent and instantly level up what it can do.
Tools & Repos
The exact tools and open-source repos behind the builds, from scrapers to agent harnesses. No guessing what stack to use.
Your Personal AI Map
GPT Genie interviews you and builds your North Star, your 10%, your 90%, and custom instructions ready to paste into ChatGPT or Claude.
The Community
Prompts, skills, and tools shared by The AI Surfer community, always growing. You are never building alone.
Sneak peek
Deploy a whole company of AI agents
One prompt each. Your agent spins off a dedicated subagent for every part of your business while your main agent stays in command.
How it works
Up and running in three steps
Create your free account
Takes 30 seconds. No credit card, ever.
Meet GPT Genie
A quick chat builds your personal AI map: your North Star, your 10%, your 90%.
Deploy your AI team
Copy-paste prompts, skills, and tools to spin up your agents and start offloading the 90%.
Ready to build your AI team?
100% free. No credit card. Just create your account and start building today.
🚀 Create your free accountNo spam. Unsubscribe anytime.